What I Learned About PostgreSQL UUID and Auto-Increment IDs
Recently, my team and I explored PostgreSQL's UUID type and how it compares to auto-incremented IDs. We ended up using a combination of both in our tables to strike a balance between uniqueness, performance, and scalability. In this post, I’ll share what I learned and how this approach worked for us.
What is UUID and How is it Different from an Auto-Incremented ID?
UUID (Universally Unique Identifier)
A UUID is a 128-bit identifier that is globally unique. It can be generated independently on different systems without the risk of collision. PostgreSQL provides built-in support for UUIDs through the uuid data type.
Comparing UUID and Auto-Incremented ID 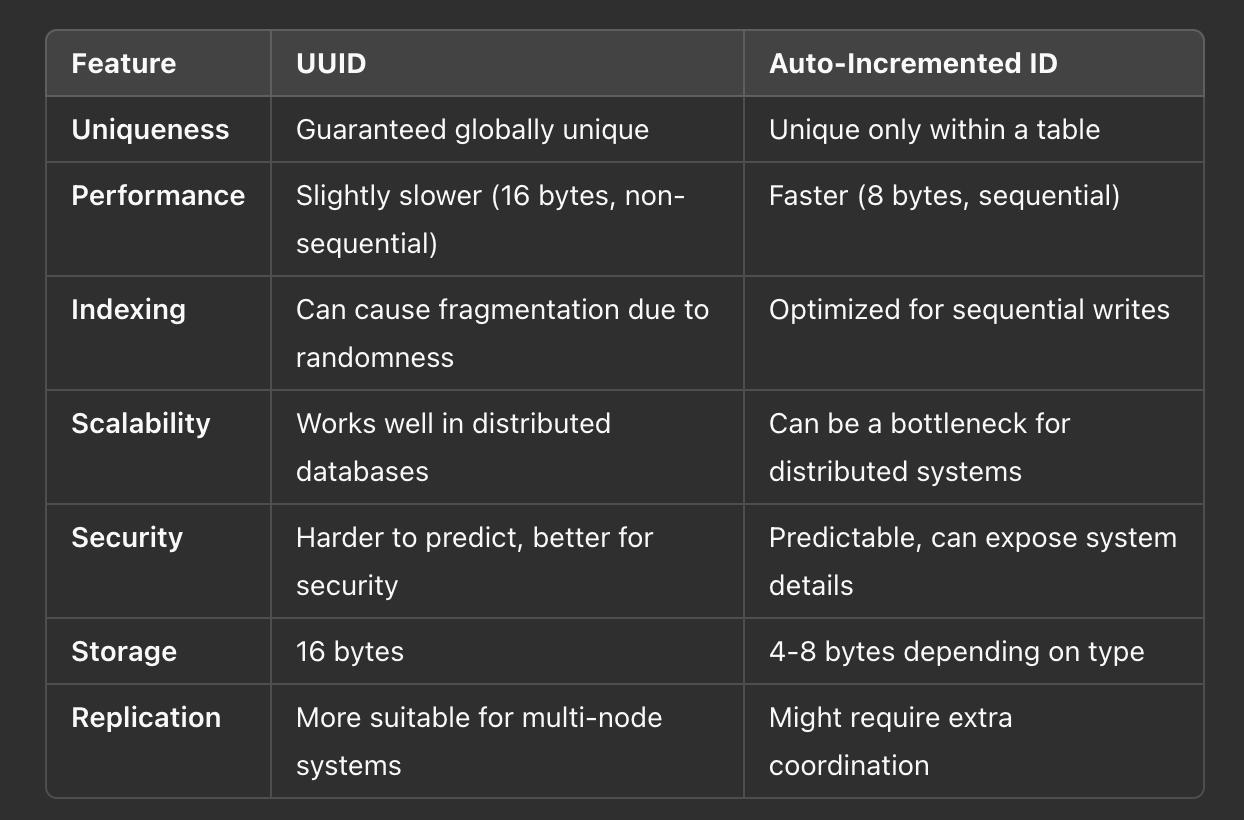
Performance Considerations
Index Fragmentation: Since UUIDs are random, they can lead to index fragmentation, making sequential scans and index lookups slightly slower.
Storage Overhead: UUIDs take up 16 bytes, while bigint (auto-incremented IDs) takes only 8 bytes, impacting storage efficiency.
Insert Performance: Sequential IDs optimize data insertion order, while UUIDs result in scattered writes, which can be a problem for high-write workloads.
How We Used Both to Boost Performance
Instead of using just one or the other, we took a hybrid approach:
Primary Key: We used bigserial for primary keys to keep indexing efficient and ensure inserts remained fast.
UUIDs for External References: We added a UUID column where unique identifiers were needed across distributed systems or external references, such as API responses.Partitioning Large Tables: In some cases, we partitioned data using UUIDs but kept the main indexing efficient with bigserial.
This approach gave us the best of both worlds—fast inserts and efficient indexing from bigserial, combined with globally unique identifiers when needed.
MySQL vs. PostgreSQL: Handling UUIDs
PostgreSQL
Native support for UUID type.
Efficient indexing with uuid-ossp extension for generating UUIDs.
Support for gen_random_uuid() in modern versions.
MySQL
No native UUID type; stored as CHAR(36) or BINARY(16), which requires conversion for efficient indexing.
Functions like UUID() generate UUIDs, but inserting them can cause fragmentation.
MySQL 8+ supports better indexing of UUIDs stored in binary format.
Which One Should You Use?
Use UUID when:
Your application requires global uniqueness (e.g., microservices, distributed systems).
Security and unpredictability of IDs matter.
You are dealing with multi-node PostgreSQL/MySQL clusters.
Use Auto-Incremented ID when:
You need performance-optimized primary keys.
Your database is single-node or not heavily distributed.
Predictability and storage efficiency are priorities.
Conclusion
Both UUID and auto-incremented IDs have their place depending on your architecture. If your system is distributed and requires unique IDs across different nodes, UUID is a better choice. However, if your primary concern is performance and storage efficiency, sticking with bigserial or AUTO_INCREMENT is the way to go.
From our experience, combining both UUIDs and auto-incremented IDs strategically helped us optimize our database for both performance and scalability. If you’re facing similar challenges, experimenting with this hybrid approach might be worth considering!